A tényszerűség kedvéért. Ez a nyílt levél a Szörcs fejlesztőinek hétfőn lett elküldve, és péntek délre ígért válaszban egyeztünk meg. Miután a az elmúlt órákban arra lettem figyelmes, hogy az általam idézett találatok kezdenek eltünni a keresőből, illetve erősen kozmetikázásra kerültek, úgy gondoltam, hogy nincs értelme tovább várni. Itt van tehát az a levél, amelyben a Szörcs fejlesztőket kérdezem bizonyos a keresőjüket érintő alapvető dolgokkal kapcsolatban, és próbálom megvilágítani és bizonyítékokkal alátámasztani, hogy mit vélek problémásnak. A levél tehát itt van, a kommentek jöhetnek, a teszteket pedig mindenki próbálja ki maga, minden nyomot úgy sem lehet eltüntetni. A lényeg kiderül a továbbiakban.
Tisztelt Szörcs.hu fejlesztők!
Többször kerestelek Titeket a Szörcs feltérképezésével és indexelésével kapcsolatban, jobbára arra irányuló kérdésekkel, hogy a Szörcs kereső milyen IP címről és milyen User-Agent-el látogatja meg a weboldalakat, amikor feltérképezi azokat. Bár a Szörcs fejlesztői blogjában (http://szorcs.hu/blog/szorcs.szorcs/user-agent/) kitértek erre a kérdésre, gyakorlatilag az ott megjelentetett adatok már magukban is érdekesek. Hivatkoztok SSO-ra, és arra, hogy a weblapok jelentős része külön kezeli a keresőket. Szakmabeliként azt kell mondjam, hogy a hazai weblapok 99%-a egyáltalán nem kezeli a keresőket, nem hogy külön kezelné.
Egyrészt azért kerestelek meg titeket, mert a fent leírtak nemcsak engem, hanem a szakmát is foglalkoztatja. Másrészt pedig mint „tartalomszolgáltató” azért várok magyarázatot, mert a piacon lévő összes valódi keresőnél felvilágosítást adnak annak érdekében, hogy a rendszergazdák, webmesterek, SEO-sok ki tudják ezeket a robotokat tiltani, ha arra van szükség. Azt hiszem, ez nem irreális elvárás.A kérdéseimre mellébeszélés-izű válaszok érkeztek.
Szeretném az érintettek segítségével és megkérdezésével blogomban bemutathatni a Szörcs valós működését, azaz: hogy vannak-e saját robotjaitok, rendelkeztek saját indexszel, vagy pedig csak a Google és Bing találatait rendezgetitek.
Leszögezném: semmi gond nincs azzal, hogy felhasználjátok ezeknek a keresőknek a találatait – más kérdés, hogy ez a Google Szolgáltatási Feltételeivel éles ellentétben áll – de akkor pl. a Johu.hu keresőhöz hasonlóan úgy korrekt, ha felvállaljátok, hogy egy másik kereső találatait rendezgetitek, tehát egy mashup jellegű szolgáltatást fejlesztettetek hozzáadott értékkel. Viszont az kommunikálni, hogy ez teljes egészében saját technológia, az inkorrekt. Megvezeti a felhasználókat és a szakmát.
Az említett Google Szolgáltatási Feltételek idevágó része : http://www.google.hu/accounts/TOS
„Ön semmilyen formában nem jogosult a Szolgáltatások reprodukálására, sokszorosítására, másolására, forgalomba hozatalára, illetve eladására, kivéve ha ezt az Ön és a Google között létrejött külön szerződés kifejezetten megengedi.”Feltevésemet alátámasztására végeztem néhány olyan vizsgálatot, melyeket bárki el tudja végezni, csak egy kis időt kell rá fordítani. Az eredmények egyértelműek bárki számára, aki hajlandó elvégezni a teszteket. Manipulációnak helye nincs.
(A tesztek alapjául ez a poszt is szolgált: http://blog.lbi-netrank.co.uk/is-ask-jeeves-scraping-google/1.vizsgálat – Új tartalom bekerülése
2010.05.23 14:21-kor élesítettem egy posztot a blogomon (seoblog.hu) a következő címmel: Három éves a SEO Blog | Boldog Születésnapot! , mely a következő URL-en jelent meg: http://www.seoblog.hu/szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/
A poszt 14:28-kor került be a Google indexébe, majd 14:30-kor a Szörcs-ön végzett kereséskor – poszt címére keresve – is megjelent.
Google találat
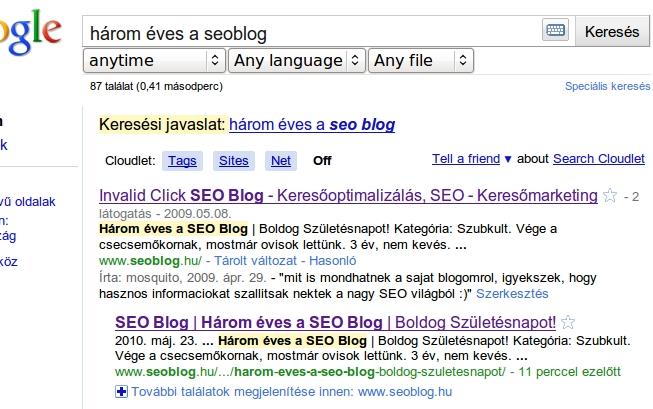
Szörcs találat:
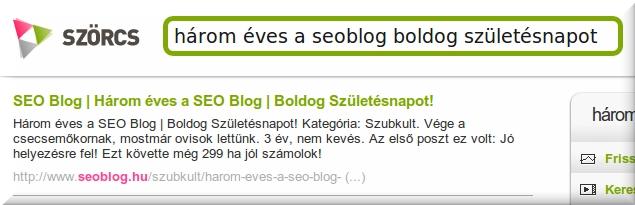
Nem volt más dolgom, mint ezt a cirka 10 percnyi webszerverlogot átvizsgálni. Szerencsére vasárnap délután volt, így aztán igazán sok szemét nem került bele.
A logokban a következő adatok voltak az említett időszak tekintetében:
66.220.155.122 – – [23/May/2010:14:17:17 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/ HTTP/1.1” 200 9394 „-” „facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php)”
66.249.65.203 – – [23/May/2010:14:20:37 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/ HTTP/1.1” 200 9394 „-” „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
212.51.122.137 – – [23/May/2010:14:25:07 +0200] „GET /images/SEOBirthday2009-300×274.jpg HTTP/1.1” 200 32652 „http://www.seoblog.hu/szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/” „Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17 NewsRob (http://newsrob.com) gzip”
188.157.124.178 – – [23/May/2010:14:25:14 +0200] „GET /images/SEOBirthday2009-300×274.jpg HTTP/1.1” 200 32652 „http://www.seoblog.hu/szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/” „Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17 NewsRob (http://newsrob.com) gzip”
67.195.112.163 – – [23/May/2010:14:25:20 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/ HTTP/1.0” 200 9394 „-” „Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; http://help.yahoo.com/help/us/ysearch/slurp)”
66.220.145.244 – – [23/May/2010:14:26:46 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/ HTTP/1.1” 200 9394 „-” „facebookexternalhit/1.0 (+http://www.facebook.com/externalhit_uatext.php)”
66.249.65.203 – – [23/May/2010:14:28:48 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot HTTP/1.1” 301 20 „-” „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
66.249.65.203 – – [23/May/2010:14:28:49 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot/ HTTP/1.1” 200 9394 „-” „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
66.249.65.203 – – [23/May/2010:14:28:51 +0200] „GET /szubkult/harom-eves-a-seo-blog-boldog-szuletesnapot HTTP/1.1” 301 20 „-” „Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”
Facebook, Yahoo! Bot, Google bot, és egy mobilról történő látogatás volt. Állításotok szerint a feltérképezés során Googlebotnak álcázzátok magatokat, így megvizsgáltam a Googlebot IP címét, mely ebben az esetben 66.249.65.203 volt. A WHOIS adatok alapján látszik, hogy ez egy, a Google birtokában lévő címtartomány. Az IP Spoofing mint olyan ebben az esetben ki van zárva.
Megállapítás: Az adott poszt úgy került be a Szörcs találatai közé, hogy bizonyíthatóan részükről nem történt feltérképezés a seoblog.hu-ra vonatkozóan, így az adott találatot egy másik kereső indexéből kellett kivenni, mely jelen esetben vagy a Google, vagy pedig a Yahoo! lehetett csak.
2.vizsgálat – IP cím és User-Agent ellenőrzésEgy vizsgálat nem vizsgálat, ezért folytattam a nyomozást, bár egy szakértő számára talán már a fentiek is épp elég bizonyítékot szolgáltatnak.
Rengeteg olyan oldal van az interneten, mely az azt meglátogató felhasználó IP címét, illetve User-Agentjét jeleníti meg.
A mi szempontunkból ez ott érdekes, hogy amikor egy keresőrobot ellátogat egy adott oldalra, akkor az ő IP címe illetve User-Agent-je generálódik ki az oldalon, amit beolvas, majd ez kerül be a kereső indexébe, és jelenik meg a találatok között. Tehát ha Bing-el vizsgálok egy ilyen site-ot, akkor ott a Bing robotjainak IP címe és User-Agent-je jelenik meg, ha Google-el, akkor az övé. Nektek ugye elméletileg van saját robototok, bár Google User-Agent-el megy, ám az IP cím – mint az első vizsgálatnál is látszik – már kritikus, mivel továbbra sem hiszem, hogy annak a spoofolását ti meg tudnátok oldani.
Itt még annyit szeretnék hozzátenni, hogy látszólag próbáljátok ezeket a találatokat valahogy kimaszkolni, gyanúsan hiányoznak az IP címek a találataitok közül.
Jöjjenek tehát a képernyőképek
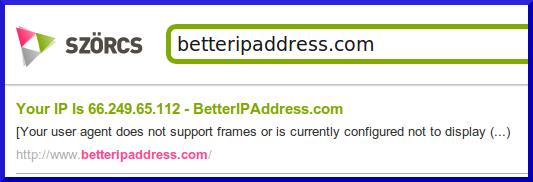
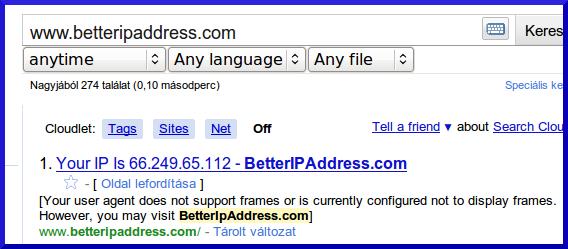
http://betteripaddress.com Szörcs, Google, és Bing találat:
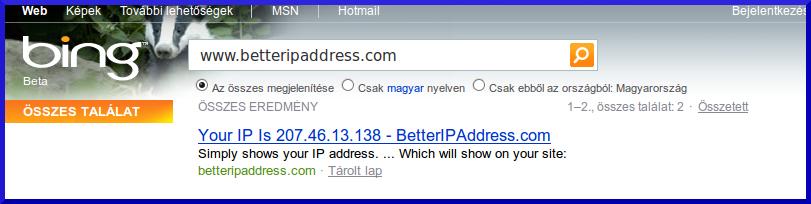
Egyértelmű, hogy a Szörcs pontosan ugyanazt a snippetet adja vissza, pontosan azzal az IP címmel, amit a Googlebot kért le. Jól látható, hogy a Bing esetében a saját robotjának az adatait mutatja.
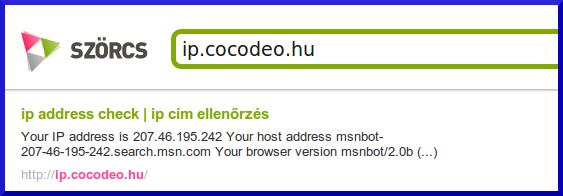
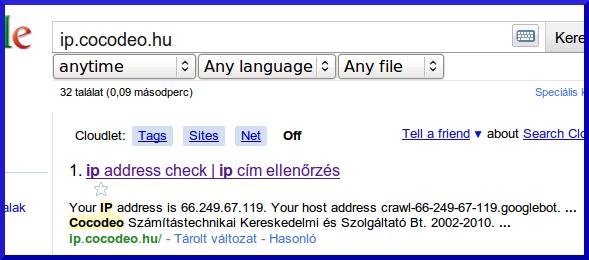
http://ip.cocodeo.hu Szörcs, Google, és Bing találat:
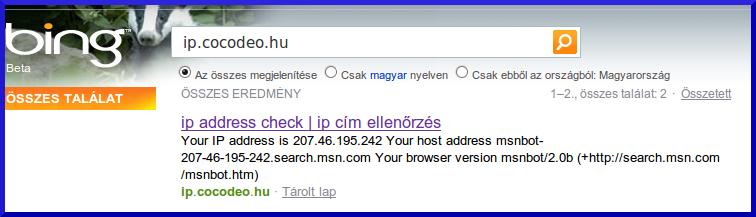
Ennél a példánál pedig azt láthatjuk, ahogy a Szörcs éppen a Bing találatát adja, a Bing robotjának az infóival. Ellenpélda a Google.
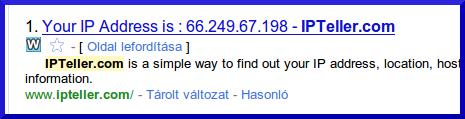
http://ipteller.com Szörcs, Google, és Bing találat:
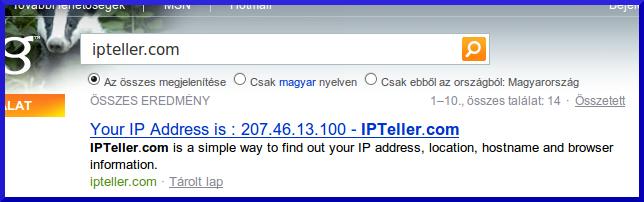
Itt is gyönyörűen látható, hogy pontosan Google találatot adjátok vissza, ugyanazzal az IP címmel, amivel a Googlebot bejárta ezt az oldalt. Ellenpélda, Bing.
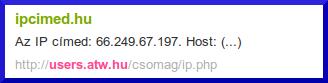
http://ipcimed.hu Szörcs és Google találat:
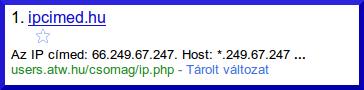
Bár itt nem pontosan egyezik a snippet, de látszik, hogy itt is egy Google IP címtartományból lekért találatot adtok vissza, Googlebot IP címmel.
Vannak még példák és screenshotok, de azt hiszem ennél több nem is kell, mindenki látja, és érti, mi a probléma.
Az lenne a kérésem, hogy a fent leírtakra (vizsgálatok, eredmények) adjatok magyarázatot, hiszen feltételezem, nektek is érdeketek, hogy az információhiányból eredő esetleges szakmai félreértések ne árnyékolják be a Szörcs image-ét, piaci sikerét. Remélem nem gondoljátok, hogy egyéni „hadjáratról” van szó, hiszen szeretném a korrekt tájékoztatás jegyében a témában érintett minden szereplőt megkérdezni, és a válaszok alapján egy hiteles, az ügy végére pontot tevő bejegyzést írni.
Kérlek Titeket, hogy 05.27.-ig küldjétek el válaszaitokat, és ha bármilyen kérdés merülne fel, keressetek bizalommal.
Üdvözlettel,
Türk István

Budapest, 2010.05.24
